Vespa provides all you need to build applications with data and AI online at scale
Serverless operations
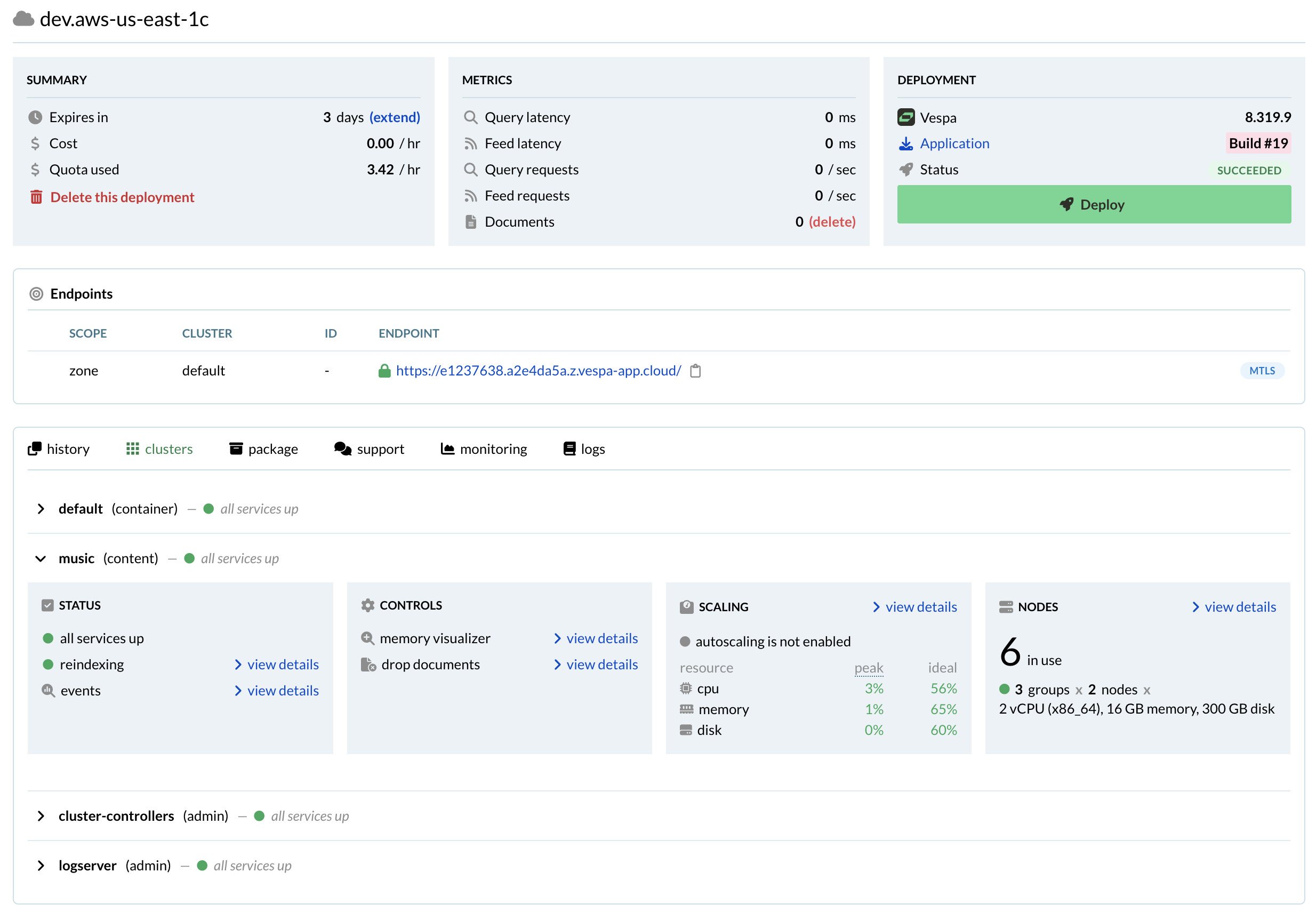
Setting up a Vespa instance for production is not hard, but operating securely and with high availability over time is challenging. Let us do this for you. The Vespa cloud provides a serverless experience to business critical operations around the globe, handling over half a million user requests per second. We will keep your Vespa applications running; you can focus on innovating with them.
Support and application tuning
Formal support by the team that develops Vespa is included when you use the Vespa Cloud, and it is the only way to get it. We guarantee responses by next business day, and since all applications run in a controlled environment where we have access to detailed telemetry we are able to resolve most problems quickly - often before they become observable by you or your users.

Automatic, safe continuous deployment
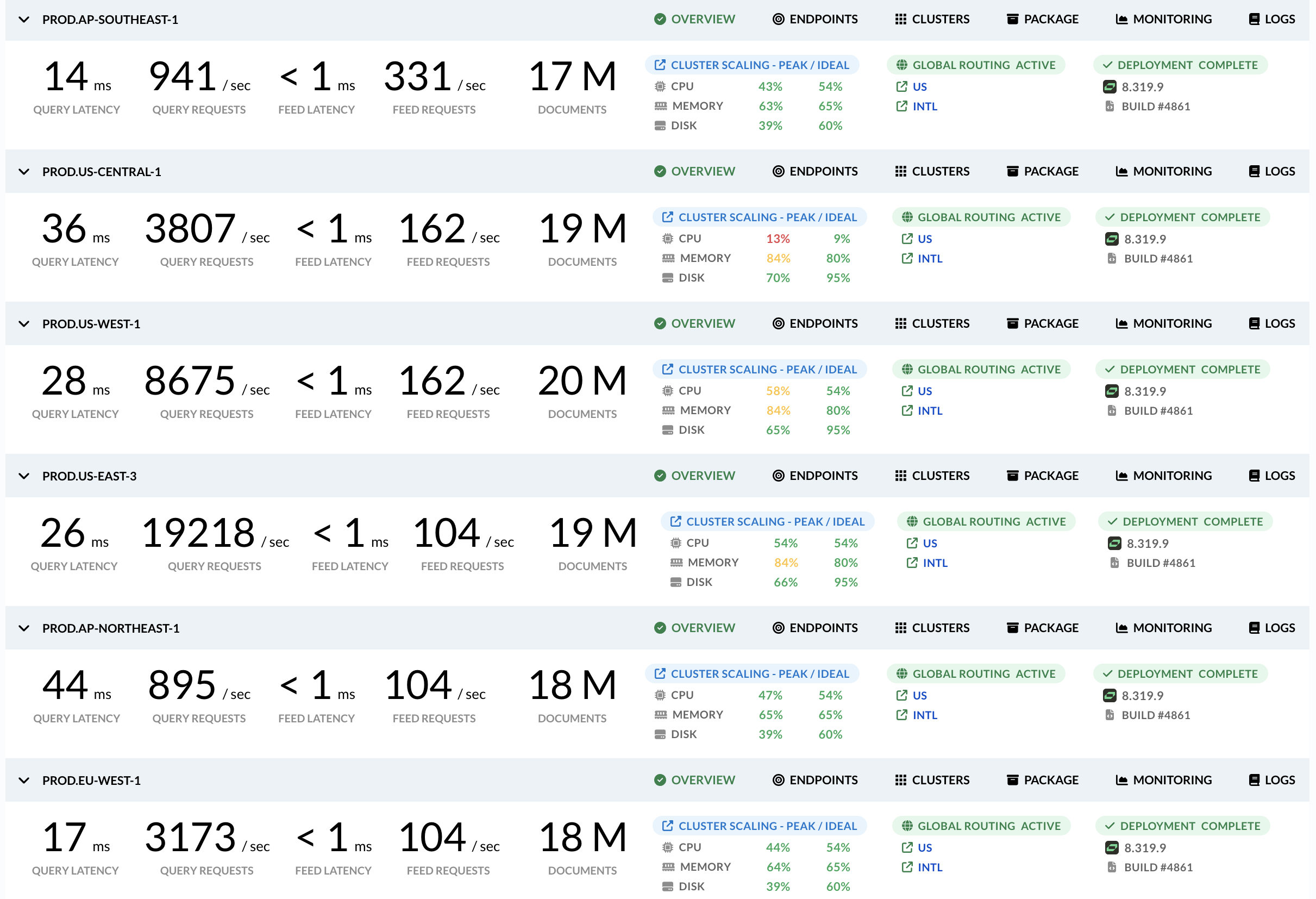
Continuous deployment - automatically deploying changes as they are made to the application source - has emerged as a best practice across the industry because deploying small increments quickly lowers risk and increases efficiency. However, following this practice on stateful, distributed, always-available systems like Vespa is challenging.
Strong security
Strong application security is more important than ever, but securing access to your application involves knowing the right security mechanisms, certificate management, etc. With Vespa Cloud, we take care of this by default; no extra steps needed. We provide you with the certificate you need and instructions on how to use it. No need for purchasing certificates, complex key management or a dedicated security team and -processes. Better let the experts handle it.

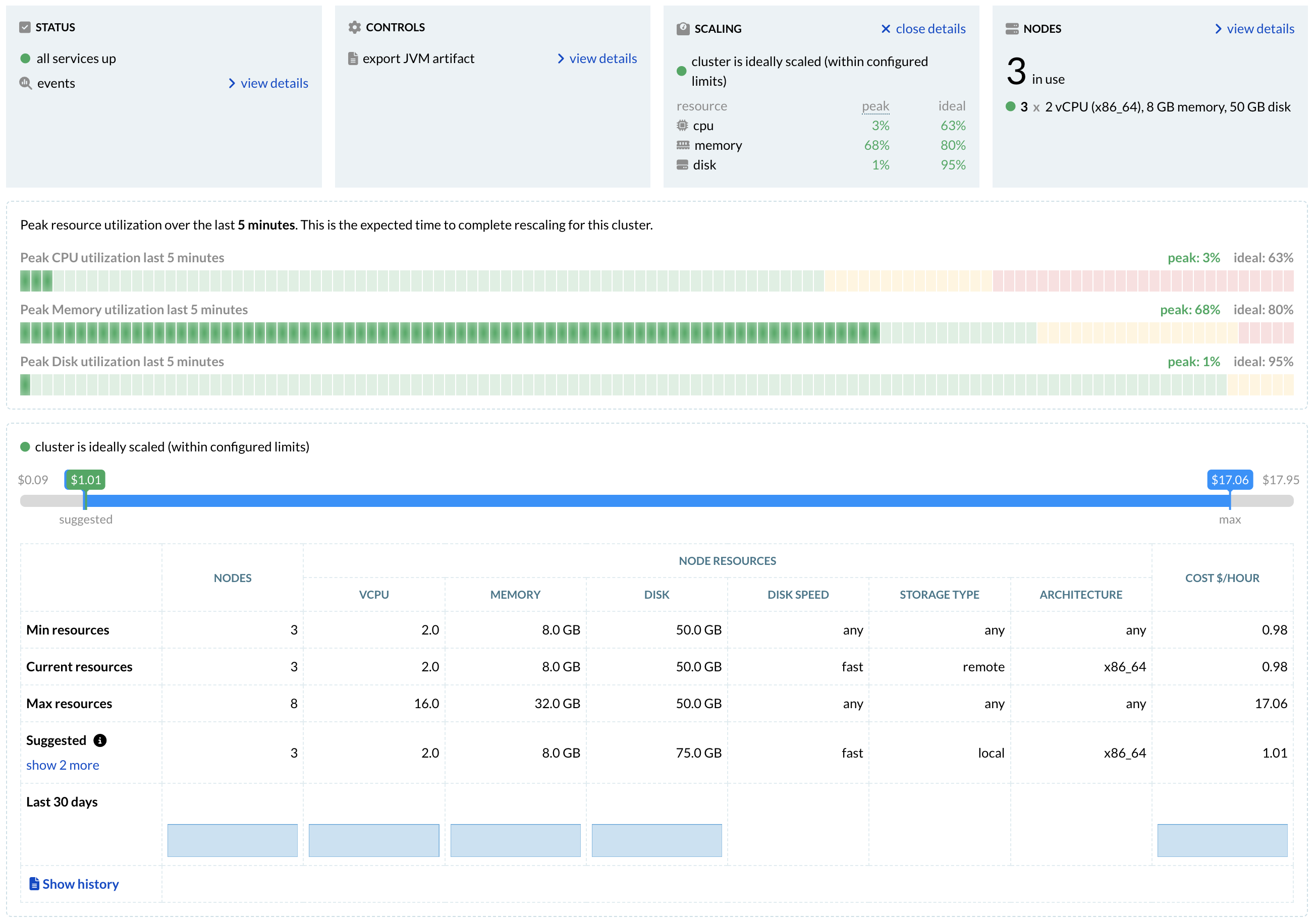
Autoscaling
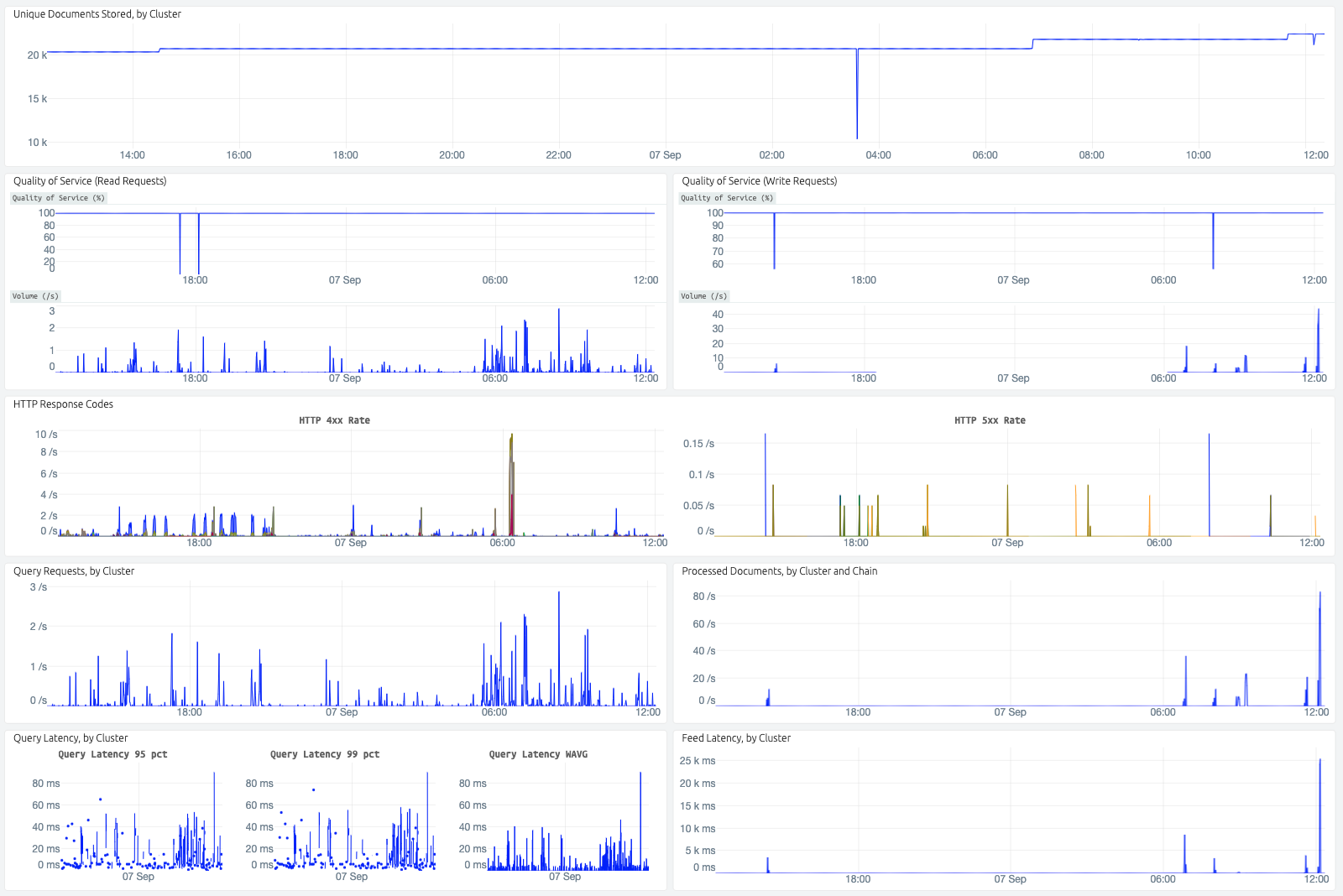
You want your application to use as few resources as possible to minimize cost, but at the same time you don't want to run out of resources when traffic is high or you feed more data.
The Vespa Cloud allows you to get both things at once by offering autoscaling on all clusters. This can often reduce the of cost of an application up to 50% by keeping it scaled to the actual needs at all times rather than always scaling for the expected peak traffic.
Developer centric
Developers should spend their time creating great products, not dealing with infrastructure and integration, getting their changes to production, or working around system limits. Vespa.ai is all about empowering developers and we have carried this ethos with us on Vespa Cloud: Developing applications are always done only by making changes to the application package, and changes are automatically rolled out in production, allowing developers to focus only on making changes in their application package source repo.